
NEXT ARTICLE
A viral accusation can travel faster than the facts that would make it legally meaningful.
That dynamic is becoming familiar in the age of AI. A product ships. A security researcher, privacy advocate, or online commentator finds a hidden-looking technical component. A screenshot circulates. The language escalates quickly: “spyware,” “surveillance,” “secret access,” “data harvesting.” Within hours, a law firm files a lawsuit (for example, a recent JetBlue alleged surveillance pricing claim that originated from an X tweet).
Sometimes, that shape is real. Some of the most important privacy and consumer protection cases begin with exactly this kind of technical anomaly: a background process, an undisclosed SDK, a quiet data transfer, a consent flow that does not match reality. These are the cases that matter. They reveal the gap between what users are told and what systems actually do.
But not every alarming technical discovery is a meritorious legal exposure. And not every hidden-looking file is evidence of harm.
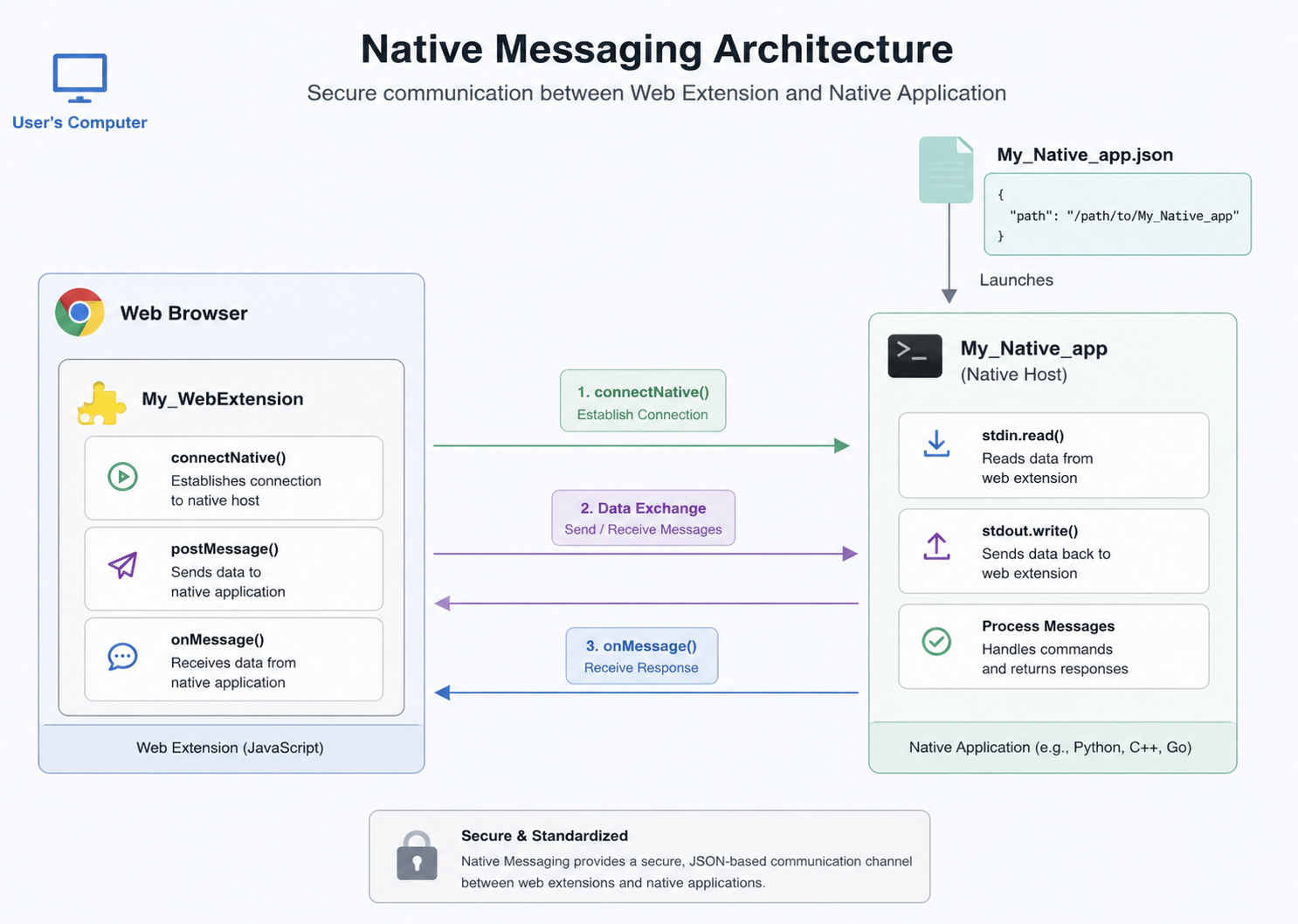
The recent online claims about Claude Desktop allegedly installing “spyware” offer a useful example. The allegation, broadly stated, is that installing Claude Desktop also installs a native messaging bridge across Chromium-based browsers, including browsers the user may not actively use. The conclusion drawn by some commentators is that Anthropic is secretly enabling surveillance across the user’s browsing environment.
That conclusion may be emotionally intuitive. It is also, based on the technical description currently circulating, likely wrong.
Plumbing is not surveillance
The key distinction is between infrastructure that could enable a feature and conduct that actually invades privacy.
Native messaging is a standard browser-extension mechanism. It allows a browser extension to communicate with a native desktop application installed on the same computer. The browser extension is one side of the bridge. The local desktop application is the other. For the bridge to matter, both sides need to exist and be configured to recognize each other.
A registered native messaging host is not, by itself, a roving surveillance agent. It does not mean the desktop app is reading browser history. It does not mean one browser can access another browser’s data. It does not mean the extension can wander through the operating system. It means that, if the corresponding extension is installed and invoked, the extension can communicate with a specific local application through a defined channel.
That may sound technical, but it is the entire case.
The more accurate description is pre-staged plumbing. The desktop component is installed in advance so that, if a user later installs the browser extension, the extension can communicate with the desktop app without requiring a second native-app installation step. This pattern is not exotic. It is common in products that connect browser workflows with local applications: password managers, productivity tools, developer utilities, meeting assistants, and increasingly, AI assistants.
While any connection between a browser and a desktop app warrants review, the dramatic claims of 'spyware' miss a fundamental reality: without the user actively installing the browser extension, this architecture is completely inert. It does nothing, collects nothing, and transmits nothing. A viable legal claim requires evidence of active data collection, not just the existence of a dormant configuration file waiting for an extension that was never installed.
On the facts currently being discussed, that is a much harder argument.

Privacy law cares about what happened
A high-value legal exposure is built on facts. For privacy risk that means: what data was accessed, what data was transmitted, what the company represented, what the user consented to, what the company concealed, and what injury followed.
A dormant or preconfigured component may raise product-design and disclosure questions. But a viable privacy claim typically needs more than discomfort with architecture. It needs conduct.
Did the extension run without being installed?
Did the desktop app collect browsing data without user action?
Did data leave the device?
Without answers to those questions, and a bunch of other ones, the case would collapse into a theory of “this looks scary.” That is not enough and should not be enough.
This is especially important in the AI context, where public trust is fragile and the appetite for enforcement is high. Any company in the world, not just AI companies, should expect intense scrutiny over data access, consent, retention, and security. They should also expect that technical design choices will be interpreted through a lens of suspicion. That is the cost of doing business today - liability is exploding.
But suspicion is not evidence. And architecture is not injury.
The real privacy problem is bigger than this
There is a deeper point here.
Users are right to be anxious about privacy. Many people have had sensitive information exposed through companies they never knowingly interacted with. Credit reporting agencies, data brokers, identity verification vendors, marketing platforms, and background data providers often hold deeply personal information that users did not affirmatively choose to share.
But precisely because the broader privacy ecosystem is so broken, legal and technical precision matters even more. When every unsettling implementation detail is labeled “spyware,” the word loses force. When plaintiffs pursue weak theories based on misunderstood systems, they risk creating bad precedent, wasting resources, and distracting from cases where companies actually did collect, sell, leak, or misuse data in ways that caused harm.
The right question for AI privacy litigators
For lawyers evaluating emerging AI privacy claims, the Claude native messaging controversy points to a broader discipline: separate the unsettling from the actionable.
The fact that software installs supporting files is not, standing alone, a privacy violation. The fact that an application prepares for optional browser integration is not the same as secretly monitoring browsers. The fact that a component is not obvious to a lay user may be relevant to disclosure, but it is not automatically deception. Don’t believe every tweet you read :)
Here are 10 questions to ask yourself if you are working through an AI privacy legal risk:
- What permissions were requested?
- Was the language clear enough in explaining the access granted?
- Did the permission cover all functionalities clearly?
- What functionality was disclosed?
- What data was actually accessed?
- What logs, network calls, or local processes show collection or transmission?
- Is the data collection or logging strictly necessary for the app's core functionality?
- Was this data shared with any third parties?
- Can this data be linked back to an individual user?
- What can actually be done with this data (e.g., targeted ads, analytics, model training)?
Those questions move the conversation from fear and ambiguity to legal intelligence and action.
Why this matters
The next generation of privacy litigation will increasingly turn on the difference between technical possibility and technical reality. AI products will live across browsers, documents, email, calendars, desktops, and enterprise systems. They will rely on integrations that are powerful, unfamiliar, and easy to misunderstand.
For companies, the lesson is to communicate clearly. If a desktop app installs native messaging components, say so. Explain what they do, when they activate, what data they can access, and how users can disable them. Acting any differently exposes you to legal costs even when a frivolous filing lands.
For lawyers, the lesson is to investigate before escalating. A compelling privacy case requires more than a viral thread. It requires a technically accurate evidence of access, collection, causation, and harm.
For insurers, the lesson is broader still: AI will generate a new wave of liability through litigation. Some exposures will be meritorious. Some will be noise. The difference will depend on whether we can identify the signal early and evaluate it before binding or paying out a claim.
That is where legal exposure management comes in.
Not every bridge is a backdoor. Not every integration is surveillance. And not every moral panic is a case. The work is knowing which ones are.